
예제의 목표

관계형 데이터베이스 (Relational Database)
왜 필요한가?
중복의 악취가 난다면 무언가를 개선할 것이 있다는 강력한 증거.
만약 1억건 이상의 행을 가진 데이터에 천만건 정도가 중복된다고 생각해보자.

중복의 제거를 위해,
원래의 topic 표에서 저자들의 부분을 별도의 표로 빼보자.
그리고 다시 topic 이라는 표를 정리해서 만든다. author의 부분에는 이름을 적는 것이 아니라 author_id값을 적는다.
표가 조금 더 복잡해지긴 했지만 중복된 데이터들은 사라지고 그 각각의 데이터들에 대한 author표의 id값으로 대체되었다.
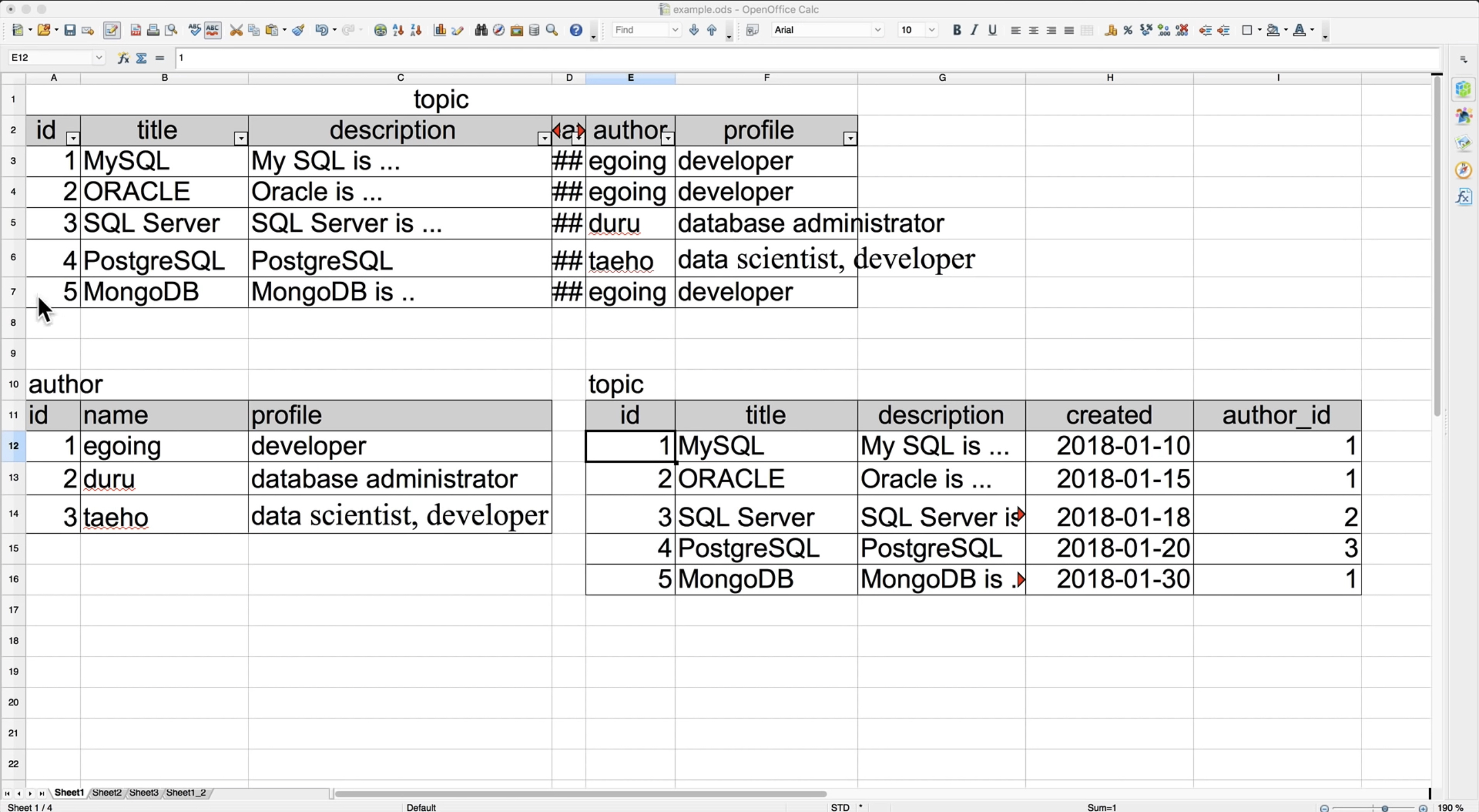
author 테이블의 name과 profile이 수정된다면 topic 테이블의 중복된 id값, 즉 원래 테이블의 수많은 중복된 값들을 일일이 바꾸지 않아도 된다는 큰 장점이 있다. (author 테이블을 참조하고 있는 topic 테이블의 모든 행이 바뀐다는 것.)
- 유지, 보수 하기가 훨씬 더 편리해졌다.
또한 동명이인이 있더라도 구분할 수 있다.
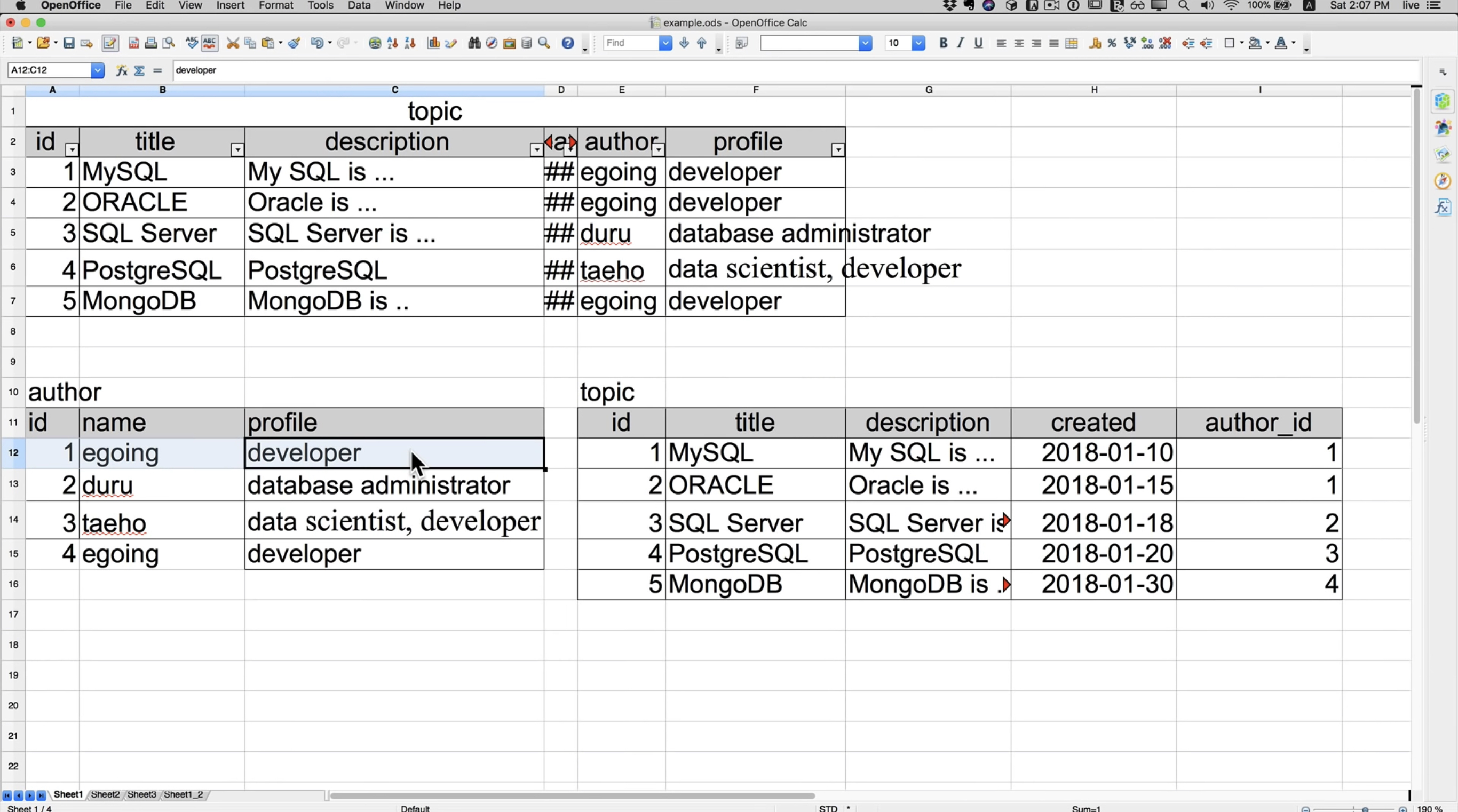
기존 위의 테이블에서 MySQL과 MongoDB의 저자가 동명이인이다. 하지만 이 테이블에서는 동명이인으로 다른 저자인지 분간하기 어렵다.
테이블을 쪼개서 id값을 다르게 설정해논다면 id값이 다르게 설정되어 있기 때문에 동명이인이더라도 다른 저자임을 알 수 있다.
Trade-off, 이러한 장점이 있는 대신 단점도 존재한다.
기존의 한개의 테이블일 경우와 아래의 두개로 쪼갠 테이블을 보면,
기존의 테이블은 모든 내용이 다 드러나기 때문에 굉장히 직관적으로 데이터를 확인할 수 있다. 하나의 테이블만 처다보면 모든 것을 알 수 있다.
반면에 테이블을 쪼개서 참조값을 넣어논다면 그 데이터 값을 볼때 그 데이터에 해당되는 그 행에 해당되는 별도의 표를 열어서 비교해가면서 봐야 하는 큰 불편함이 있다.
그래서 우리는 데이터를 별도의 테이블로 보관함으로서 중복을 발생시키지 않고(중복의 제거를 했고) 데이터를 볼 때에는 기존의 테이블처럼 하나의 데이터, 테이블로 보고 싶다.
이것을 MySQL와 함께라면 가능하다.
다음 시간에 문법들을 알아보자.
'youtube.com|user|egoing2 > DATABASE2 MySQL' 카테고리의 다른 글
| DB2 MySQL - 17. JOIN (2) | 2021.12.30 |
|---|---|
| DB2 MySQL - 16. 테이블 분리 (2) | 2021.12.30 |
| DB2 MySQL - 9. CRUD (10-13. INSERT/SELECT/UPDATE/DELETE) (0) | 2021.11.27 |
| DATABASE2 MySQL - 8. 테이블의 생성 (2) | 2021.11.26 |
| DATABASE2 MySQL - 7. SQL과 테이블의 구조 (2) | 2021.11.24 |